
Recently, I was working on a back-office application. It started easy like a CRUD application. But we’ve added a lot of processing in the application. Data-oriented processing.
This means visualization, export, search systems and more.
Every little time, a page starts to get slow. Really slow.
This is due to the amount of data being handled which increases as the application continues getting big. And sometimes it’s due to new features or more data to display.
So, every little time, I have to solve the performance issues. I’ve been requested many times to speed up the response time of those endpoints. And each time I handle the situation the same way.
I will list four ways I use to optimize an endpoint. I apply them in the same order.
Once an endpoint becomes slow due to more features or more complexity, I go to the next optimization solution.
HashTable mapping
This is also called memoization.
Most of the endpoints have for-loops. In those for-loops there are database requests. When the loops are long, this makes a lot of database requests.

A solution I always apply is fetch all the necessary data before entering in the for-loop. And store this information in a HashTable. With the ID as the key.
Using a HashTable instead of a list reduces the access time to each element. As I will read the elements by ID, I don’t have to iterate the whole list to get the element.
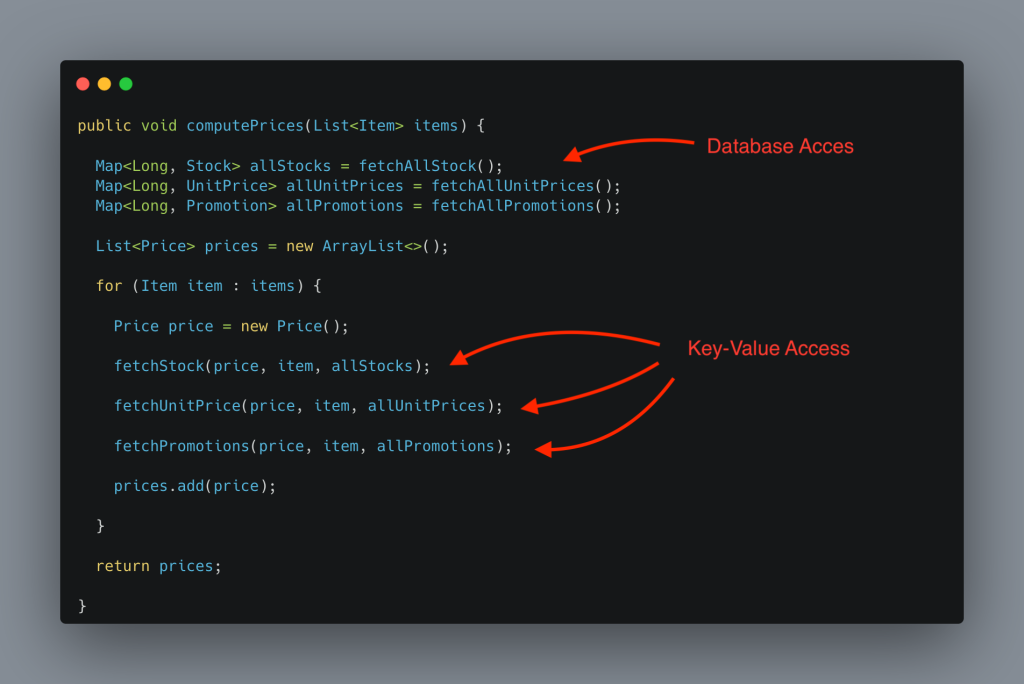
The HashTables knows the exact position of each element given it’s ID.
This solution goes from N database requests for M loops (which does N x M database requests) to only N database requests.
Even if the requests are bigger as they read more data, it’s faster to read once more data, than read many times few data.
Pagination
Sometimes, the data read is too much. Too much for the database, too much for the application, too much for the HTTP request or too much for the frontend.
To split this data in small chunks, I can use the pagination. It consists by defining in the frontend how much data I want (how many elements), which page (how much data to skip from the first element), and which sort criteria to choose.
This pagination information goes until the database request. This way, the data retuned by the database is smaller. The less data is returned by the database, the less data I have to compute in the application, the faster it goes.
The trick with the pagination is to choose a fixed sort order or let the frontend define it. Because the pagination has to sort the data to determine which page is the requested.
Denormalization
When fetching data from the database, most of the time I need to query many tables. Sometimes I have to compute values accros many tables to obtain the requested data.
The compute and the joins are expensive operations.
A solution to minimize those operations is to denormalize the data in the database.
This means that I duplicate some information in the database in order to speed up the response time.
To obtain the total population of a city or country, I may need to count all the people linked to a city.
Why don’t store an aproximative value int the city table? This value can be updated once per night.
To read all the details of a city, I may need to join the country table.
Why don’t copy the country information in the city table?
This way I avoid joining two bug tables when I request the information.
Duplicating data consumes more storage, and it requires more complexe updates mechanisms. But the response time is significantly optimized.
Cache
When all of those methods are not enough to optimize the response time of my application, I use the cache.
Using cache to store the response body of some endpoints is the best way to optimze the response time.
Nevertheless, it comes with some complications.
It needs an additional server, a cache server. Redis is a good choice.
This solution also requiers to store the data with the adecuate key. The key is the element needed to read the data back.
The cache works as a key value storage system. The key needs to be as similar as the request body as possible. Taking into account the parameters requested, the user which made the request, and other factors.
Another point that must taken into account is the validity time of the stored data. Does the data always remain valid? Will it be outdated on the next day? On the next hour? Or upon a user’s action?
I must invalidate the cache as soon as the data is outdated. I must identify all the places in the application where I need to invalidate the cache.
And depending on the actions, I may need to invalidate a single cache entry or all the cache.
And the last point is what happens once the cache is invalidated? Do I wait until the next request to fill the cache? Is it acceptable that this first request will be slow? Or do I fill the cache programmatically?
It depends on you.
Conclusion
When I find an endpoint which has a long response time, I apply those 4 steps one by one until the response time is acceptable.
I’ve done this several time in this order. As the complexity increases as I go down in the list.

Leave a comment