
It has been a decade since we first encountered the concept of Microservices Architecture. 10 years implementing applications with many Microservices. Separating the logic, handling the communication between them, configuring the resources independently…
On the other hand, Serverless Architecture made its debut five years ago. 5 years implementing servers that start-up upon arrival of the first request, and it’s able to scale up to thousands of servers.
Now, the big question arises: which of these architectural paradigms is superior?
Recently, I faced this decision. I had to choose between using a Microservices Architecture or using a Serverless Architecture.
The catch is that I already had the Microservices Architecture working, but several questions made me rethink the architecture.
Microservices Architecture Description
The Microservices Architecture tells us to separate the logic in many applications.
The goal is to be able to have the whole application working with different loads of small services. This means that I can focus on the server resources for the customer website over the back-office.
This also means that I can have many different teams working on each service. With different technologies. And different rollout cycles.
However, these advantages also come with some drawbacks. It requires a deeper understanding of the network. It requires a higher level of service orchestration. And if handling different technologies, it requires more people.
Serverless Architecture Description
With the Serverless Architecture, I also have many different services deployed independently.
As with the Microservices, each service can be managed by a different team, with different technologies and different rollout cycles.
But this time, the level of orchestration is different.
The network management is different. Let’s take the example of AWS Lambda. I must manage the roles to allow a Lambda to request another Lambda. This time, it’s not a web request, but an internal API request, done with the AWS CLI.
With the Serverless Architecture, I don’t need anymore to calibrate the load for each service. Once a service is no longer requested, it shuts down. And if the load increases, many instances are automatically scaled up.
Advantages and Disadvantages of Microservices
Let’s pick a typical example of Microservices Architecture.
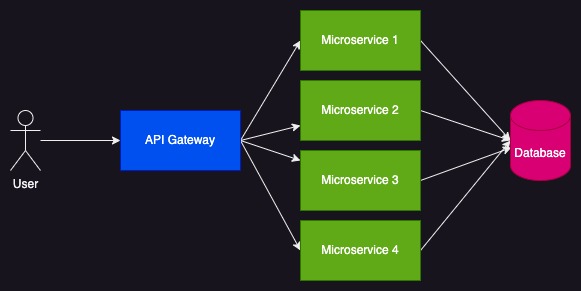
A user’s request can reach one or many Micorservices, and each Microservice can access the database. Knowing the amount of Microservices, I can configure easily the thread pool of the ORM and the accepted connections in the database.
The number of connections will be stable. Even if the load increases. As the ORM will reserve the connections at the startup and maintain them idle.
On the other side, when the load increases, I have two possibilities.
I can create auto-scaling rules, to create new instances upon the new load. And I must create similar rules when the load decreases.
I must apply those rules both to the instances of the Microservices and to the server instances which run all my cluster.
The rules can be complex. As I can configure them by amount of requests, by CPU or memory consumption.
But what if it’s the CPU which increases due to a single thread? More instances will be created.
What if the user’s requests increase faster than my cluster is able to create new instances?
The alternative is to keep a fixed number of resources. This implies that in case of a surge in load, any excess will be disregarded. However, if a particular instance is shut down for any reason, the architecture will automatically restart it to uphold the original resource count.
This seems a bad configuration, but in fact it has many advantages:
- it keeps the costs stable;
- it keeps the application running after any disaster;
- it simplifies the configuration.
Advantages and Disadvantages of Serverless
When using Serverless applications, I don’t know how many services can be executed at once. Configuring the database connections can be harder.
Using an ORM for each Serverless instance won’t solve the problem, as each instance will consume a physical connection to the database.
On the other side, I must configure the resources (CPU and Memory) for one execution. If the load increases, more instances will be started with the same configuration.
With the Serverless configuration, I don’t need to care about auto-scaling rules. Each instance will only handle a single request.
This means that I can configure the resources of my Serverless application to be near 100% all the time.
Conclusion
In my own experience, I have chosen to use a Micorservices Architecture when:
- I have a stable load;
- The bottleneck of my application is the database;
And I prefer to use a Serverless Architecture when:
- I have rare executions;
- I have scheduled operations;
- I want to scale up the CPU and Memory easily.
And of course, I’ve also used a combination of both solutions. Having Microservices with stable load and some Serverless services for scheduled operations.

Leave a comment